FRIF TE E1N Evaluation
These comments provided by Neurotechnology are based on the submission results, reviewed on May 19, 2026.
In May 2026, Neurotechnology's fingerprint identification algorithm, submitted as Neurotechnology+0106, achieved first place in the majority of NIST FRIF TE E1N test categories. The submission ranked first in Class A (index finger identification) and first in Class B multi-finger and identification flat experiments, including zero-error results in four experiments. In Class C (ten-finger identification), the submission ranked second among 11 participating organizations.
What is FRIF TE E1N?
FRIF TE E1N (Friction Ridge Image and Features Technology Evaluation Exemplar One-to-Many) is a technology evaluation run by the National Institute of Standards and Technology (NIST). It tests the template creation and search algorithms that form the core of Automated Biometric Identification Systems (ABIS) – the large-scale systems used in national identity programs, border control, and law enforcement to match fingerprints against enrollment databases of millions of records.
In the evaluation, participating organizations submit their fingerprint algorithms to NIST. NIST then measures how accurately each algorithm identifies subjects by searching probe fingerprints against large reference databases, and how reliably it creates fingerprint templates without failures.
See the NIST FRIF TE E1N official page for more information. The May 2026 results include 11 participating organizations from North America, Europe, and Asia.
FRIF TE E1N testing process
The evaluation is structured around three test classes, each representing a different operational scenario for large-scale fingerprint identification:
- Class A – Uses plain impressions of the left and right index fingers, tested both as individual fingers and as a two-finger combination. Algorithms are searched against a database of 1.6 million enrollment records. In operational terms, this reflects travel-document use such as electronic passports, which typically store two fingerprints – commonly the index fingers.
- Class B – Uses Identification Flat captures (slaps) in a 4-4-2 configuration: right slap, left slap, and two thumbs. Algorithms are searched against a database of 3 million enrollment records. In operational terms, this reflects large-scale civil identification – such as national ID programs, voter-registration de-duplication for elections, and border-control checkpoints – where a system receives simultaneously captured multi-finger impressions and must identify the subject against a full ten-finger enrollment database.
- Class C – Uses plain impressions of all ten fingers in a 4-4-1-1 configuration. Algorithms are searched against a database of 5 million enrollment records, making this the most demanding test class in terms of database scale. In operational terms, this reflects law-enforcement and forensic use, where rolled ten-finger impressions captured during booking are searched against large criminal databases.
NIST measures accuracy using two complementary metrics:
- FNIR @ FPIR – False Negative Identification Rate at a given False Positive Identification Rate. This measures how many subjects are missed when the system operates in a fully automated mode at a defined error tolerance. The FPIR sets that tolerance: it bounds how often a search returns a false candidate above the threshold. Ideally, at a fixed threshold no false candidate is returned – but one can appear when the searched subject is not enrolled, and it can also be returned alongside the correct match when an enrolled subject is searched. An FPIR of 0.001, for example, corresponds to about 1 in 1,000 searches returning such a false candidate. The FNIR is then the fraction of enrolled subjects still missed at that setting, so a lower FNIR indicates fewer missed identifications. Also called the Identification metric.
- FNIR @ Rank – False Negative Identification Rate at a given rank. This measures how many subjects are missed when a human examiner reviews the top candidates returned by the system. The rank is the position at which the correct match appears in the candidate list, and NIST reports this metric at several ranks rather than at a single one. A search counts as successful at rank N when the correct candidate appears among the first N candidates the examiner reviews – so rank 1 requires the correct match to be the top candidate, while a higher rank also accepts it as the n-th candidate further down the list. This is also called the Investigation metric, because the candidate list is normally reviewed manually during an investigation.
Evaluation results for submission Neurotechnology+0106 are provided below for each test class. All testing was performed by NIST on Intel Xeon Gold 6254 hardware in single-threaded mode.
Class A – Index Finger Identification
Class A tests identification using plain impressions of the left and right index fingers, searched against a database of 1.6 million enrollment records.
Neurotechnology's algorithm ranked first (tied with one other participant) among 11 organizations in the Class A identification metric. The algorithm achieved an FNIR of 0.0002 at all tested FPIR thresholds (≤ 0.001, ≤ 0.005, and ≤ 0.01), meaning that out of approximately 10,000 mated probes, fewer than 3 identifications were missed regardless of the operating threshold. The same FNIR value of 0.0002 was observed at all candidate ranks from 1 through 100, indicating no degradation when a wider candidate list is reviewed.
Template creation produced zero failures across all probe and reference image sets.
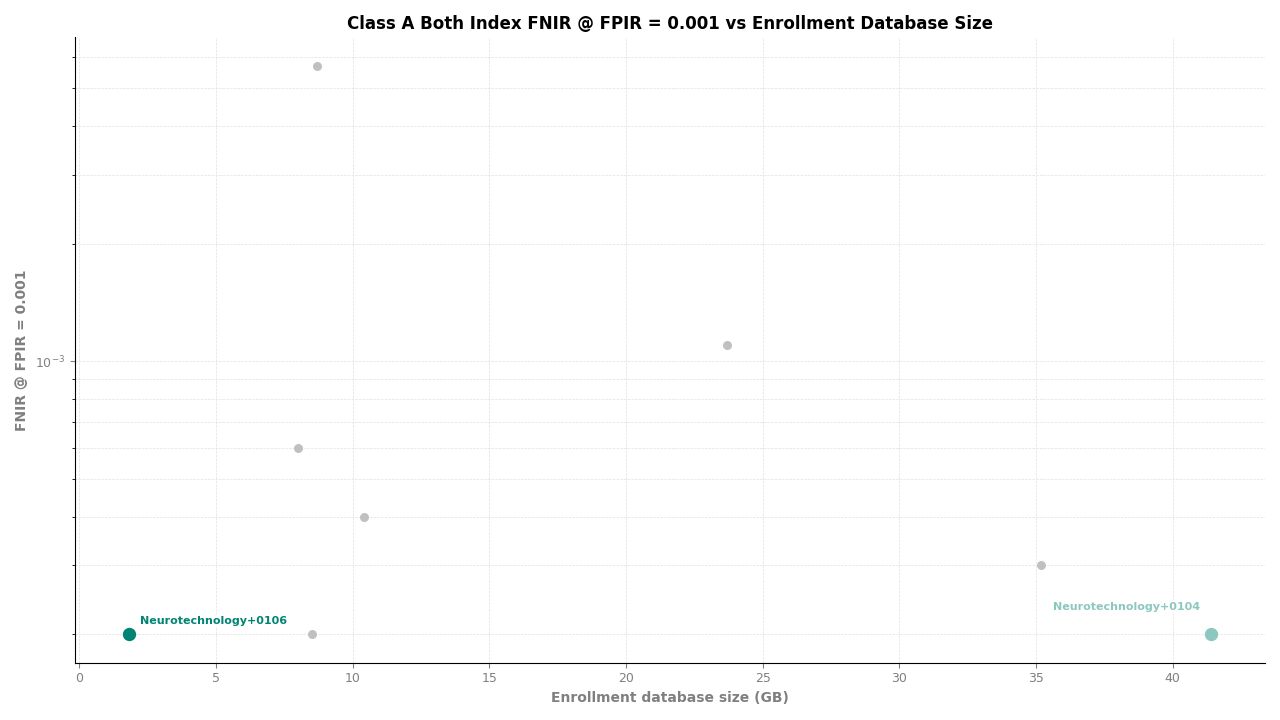
Both Index – FNIR at FPIR ≤ 0.001 vs. Database Size
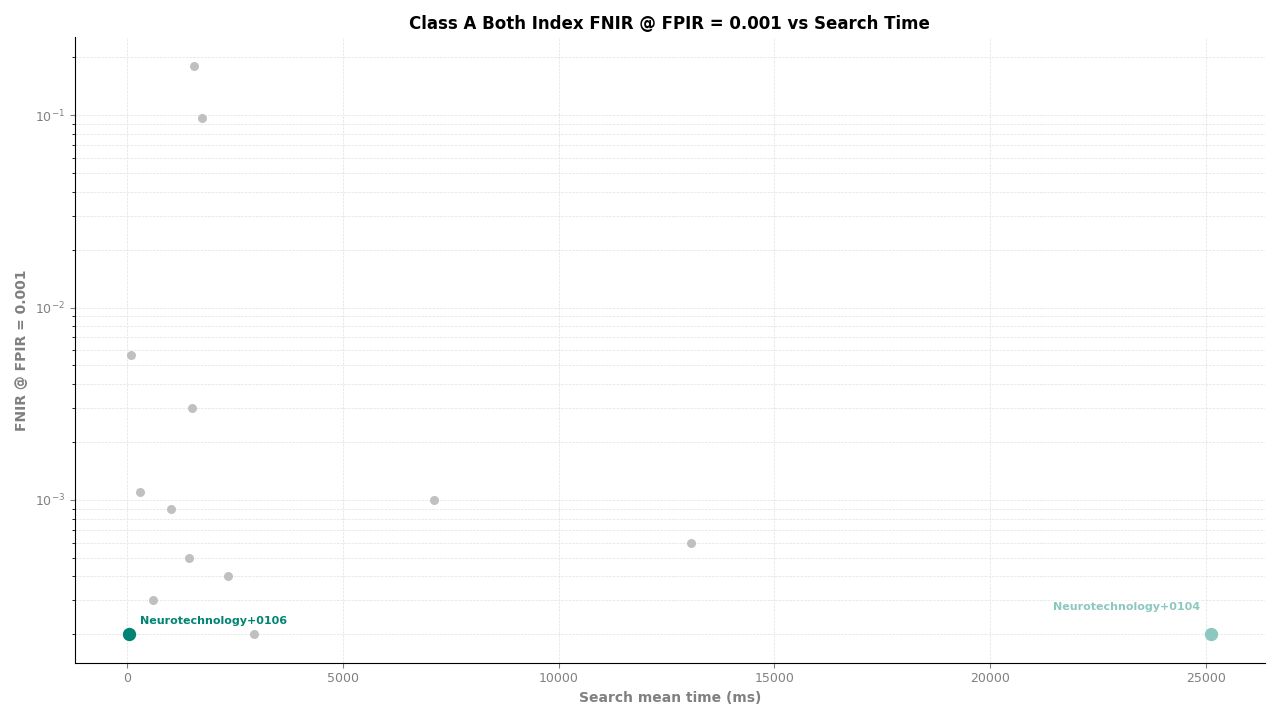
Both Index – FNIR at FPIR ≤ 0.001 vs. Search Time
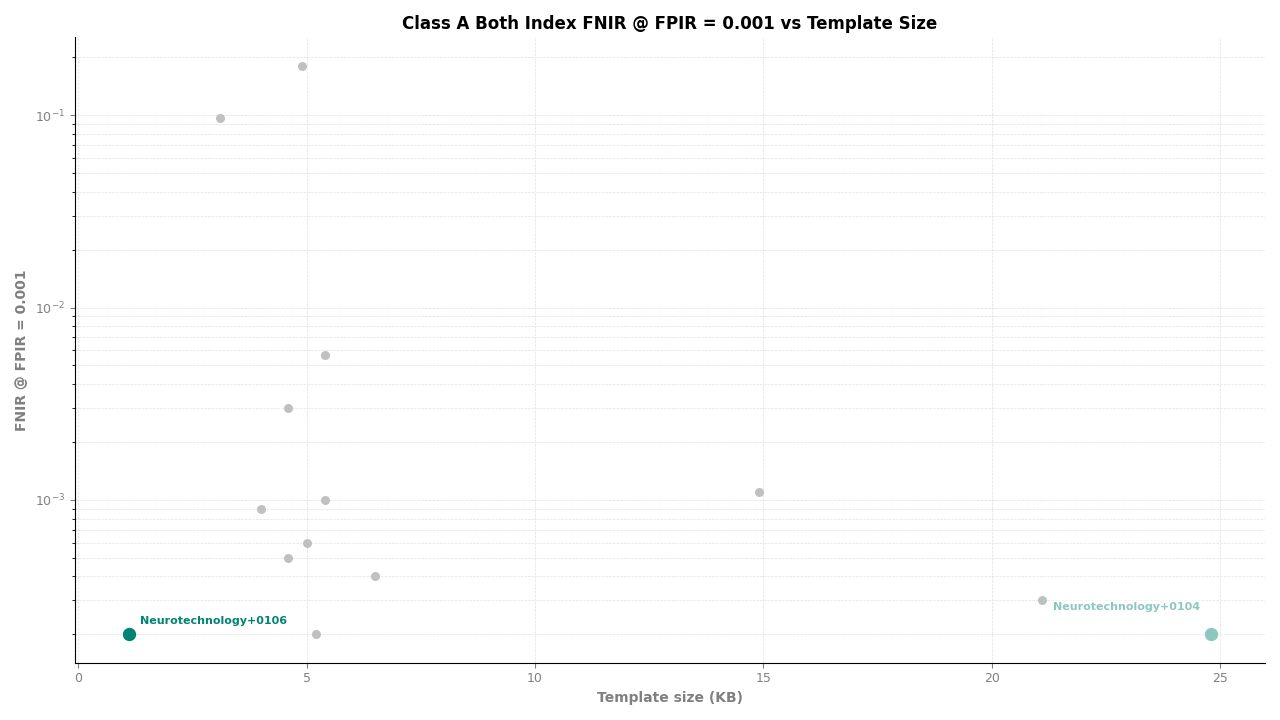
Both Index – FNIR at FPIR ≤ 0.001 vs. Template Size
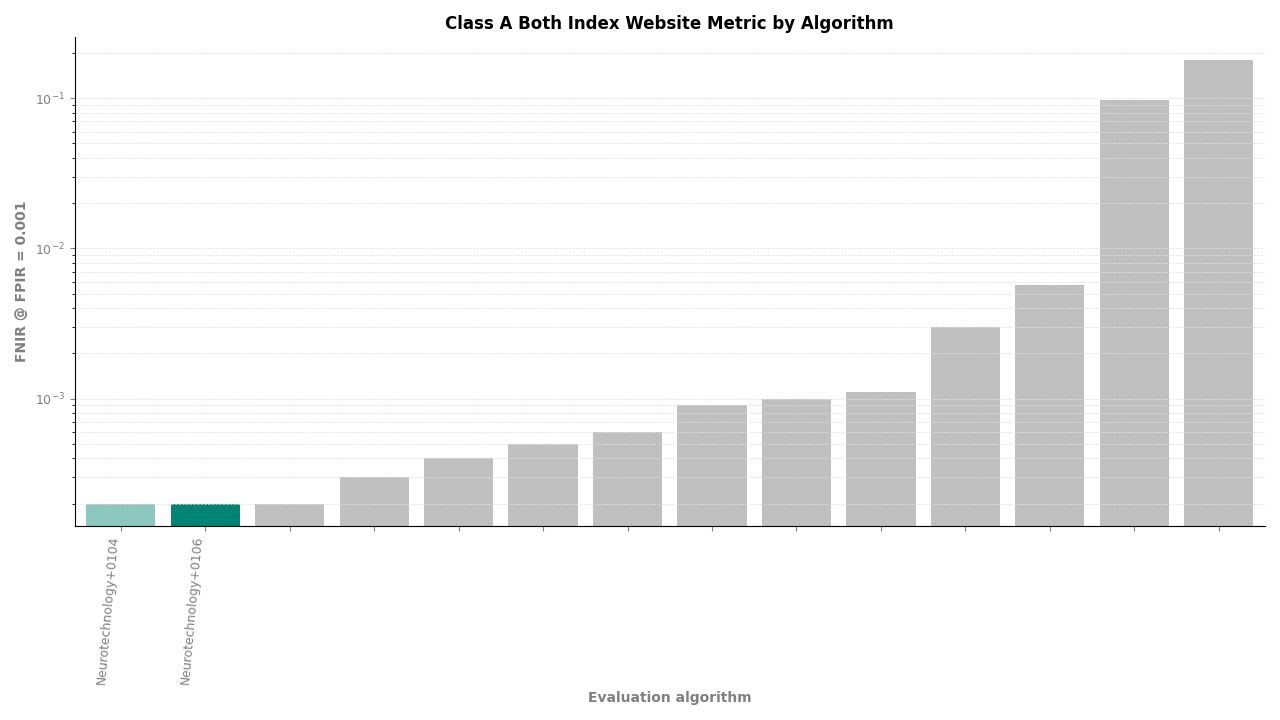
Both Index – FNIR at FPIR ≤ 0.001 by algorithm
Class B – Slap and Identification Flat Identification
Class B tests identification using slap captures in a 4-4-2 configuration, searched against a database of 3 million enrollment records.
In the multi-finger experiments – left and right slap combined, and identification flats – Neurotechnology's algorithm achieved an FNIR of 0.0000 at all FPIR thresholds and at all candidate ranks from 1 through 100. This means zero missed identifications among all mated probe searches in these experiments. These are the results where NIST records the metric as exactly zero.
For individual slap probes (left slap and right slap searched separately), the algorithm ranked second of 11, achieving an FNIR of 0.0002 at FPIR ≤ 0.001. Template creation produced zero failures across all probe and reference image sets.
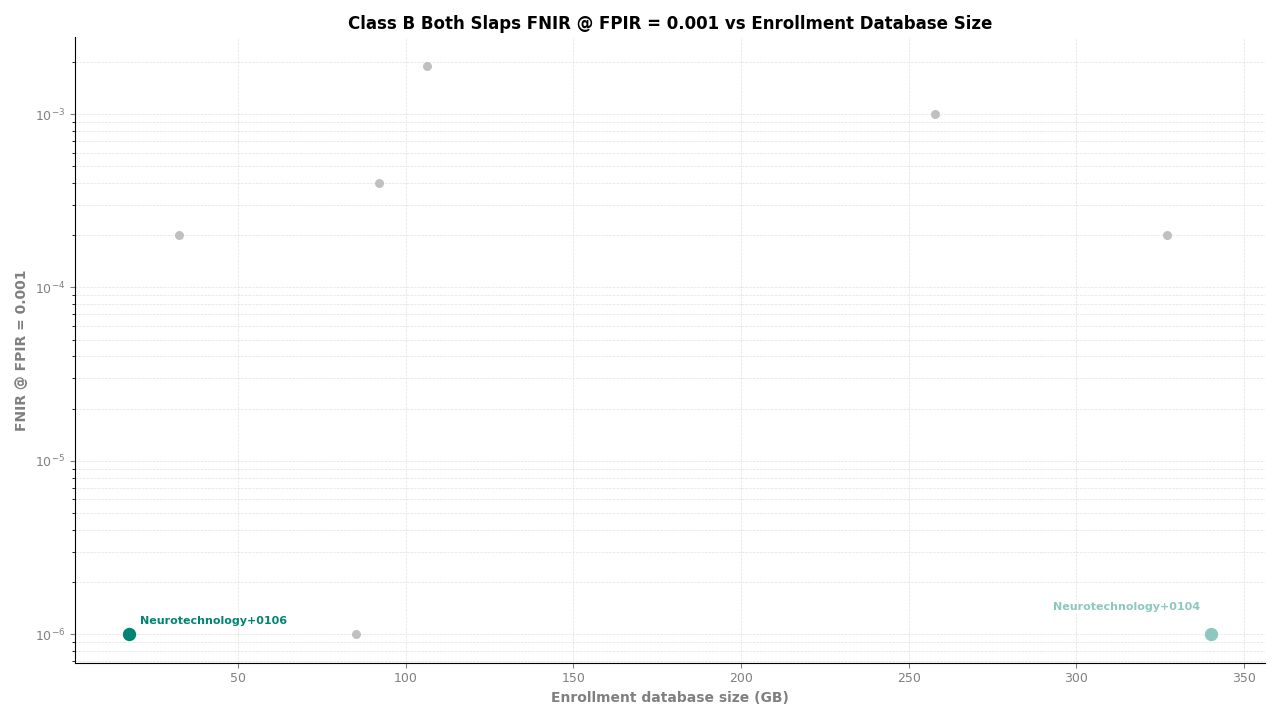
Both Slaps – FNIR at FPIR ≤ 0.001 vs. Database Size
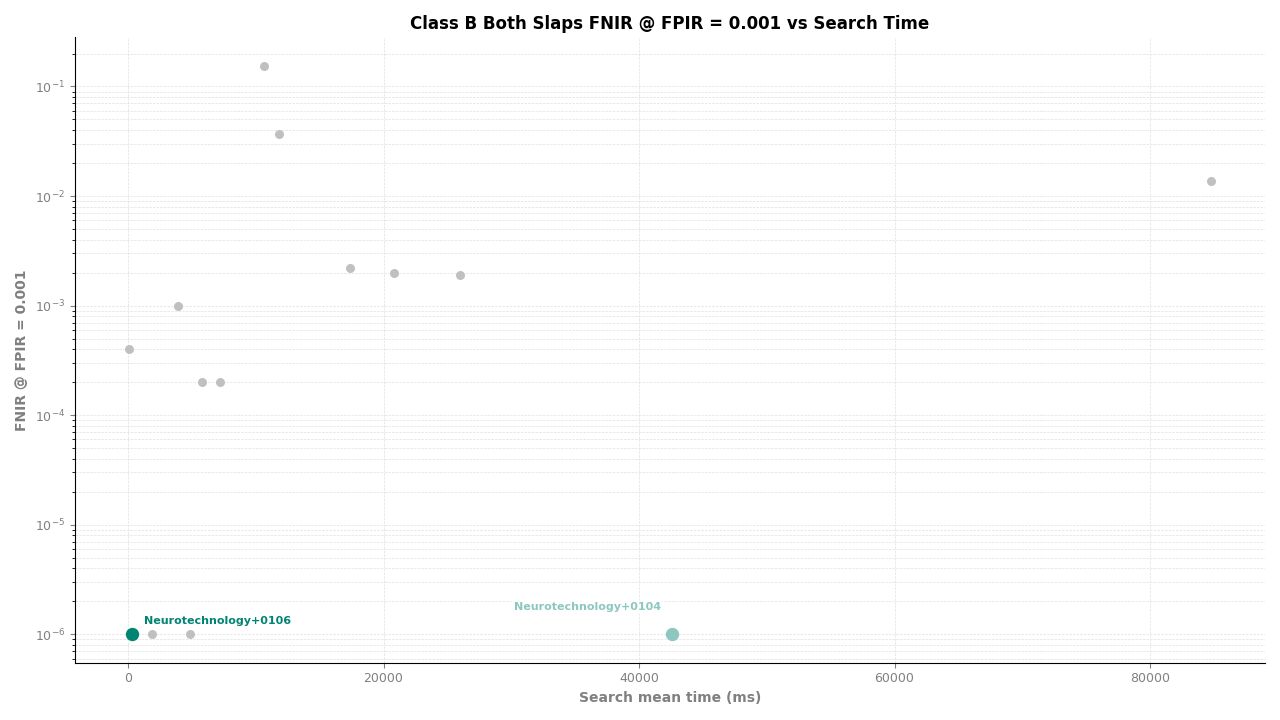
Both Slaps – FNIR at FPIR ≤ 0.001 vs. Search Time
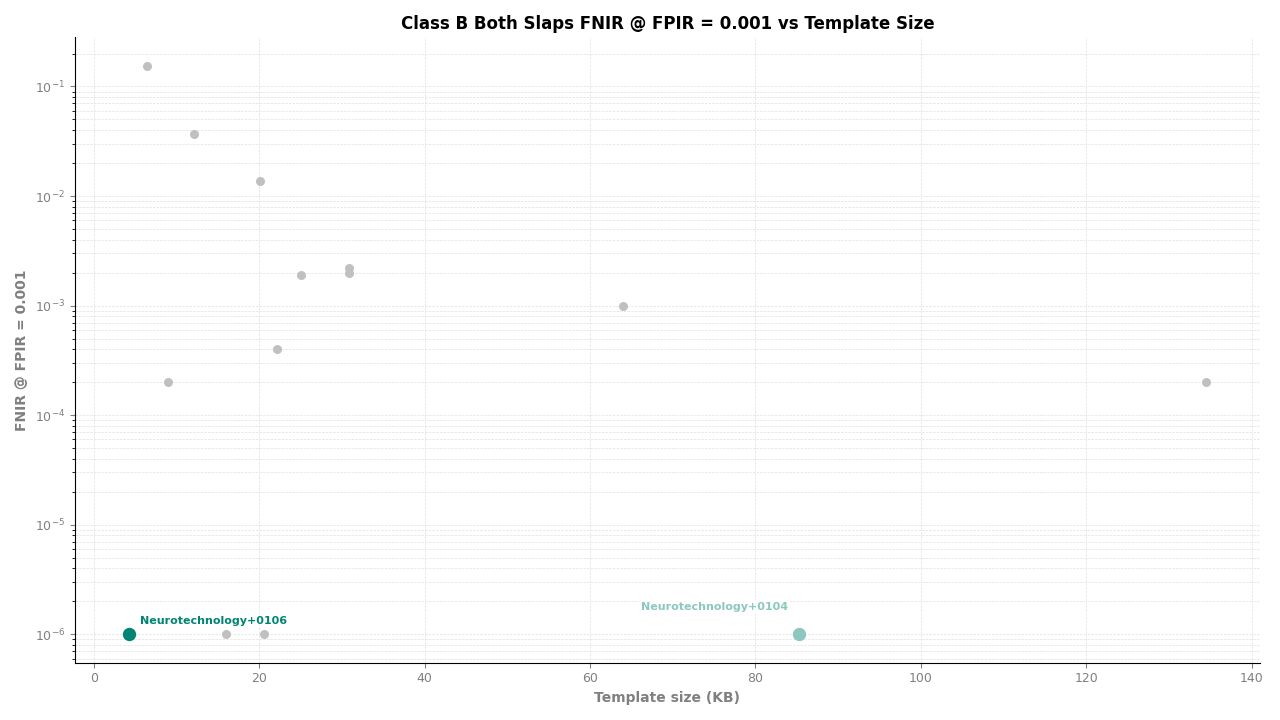
Both Slaps – FNIR at FPIR ≤ 0.001 vs. Template Size
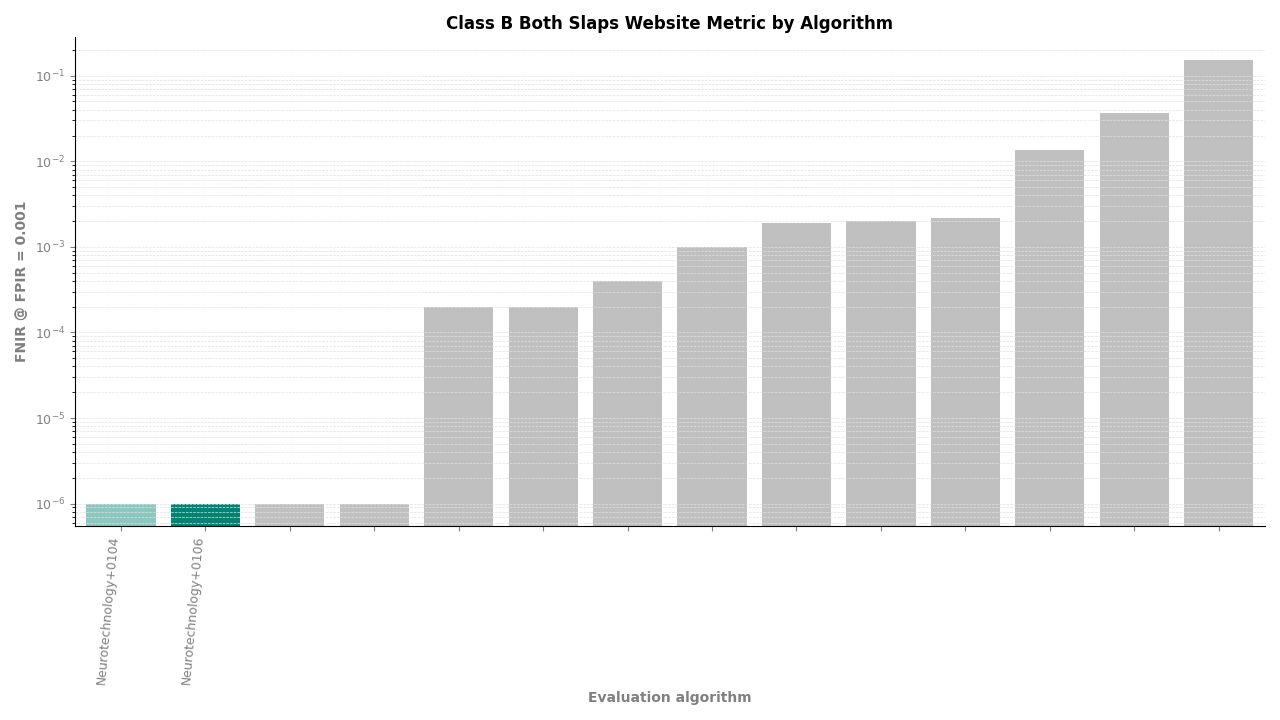
Both Slaps – FNIR at FPIR ≤ 0.001 by algorithm
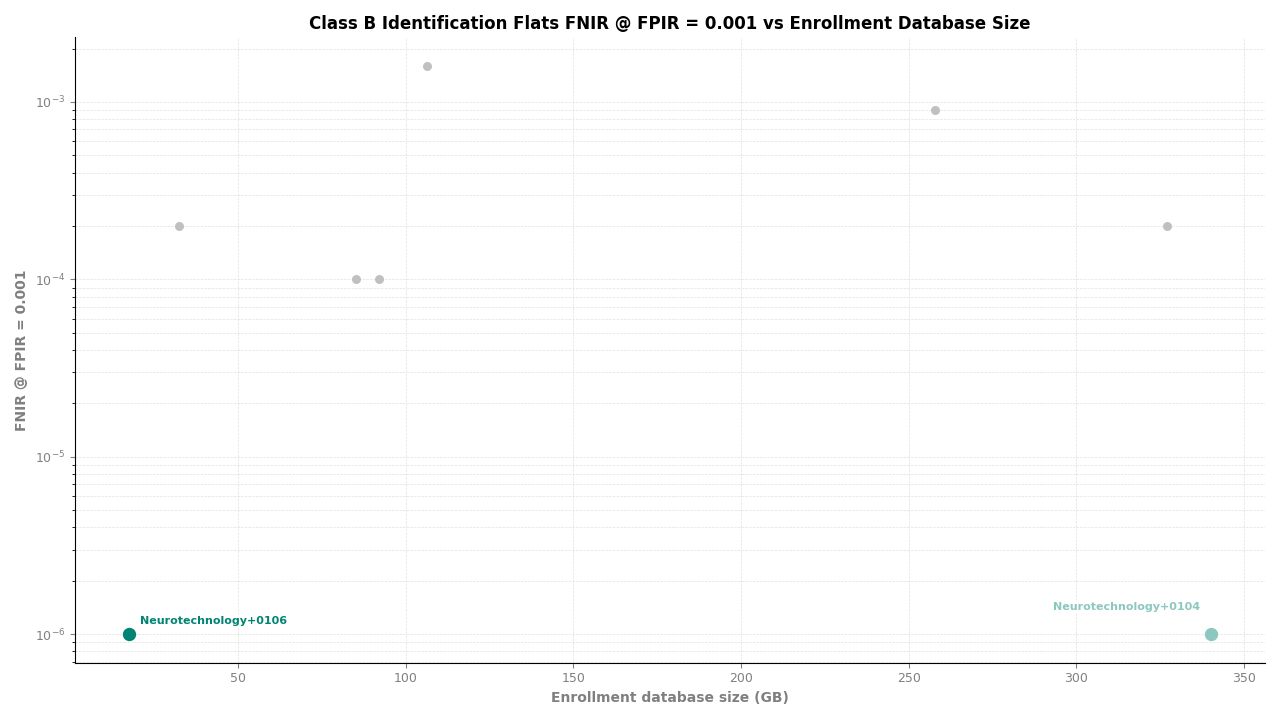
Identification Flats – FNIR at FPIR ≤ 0.001 vs. Database Size
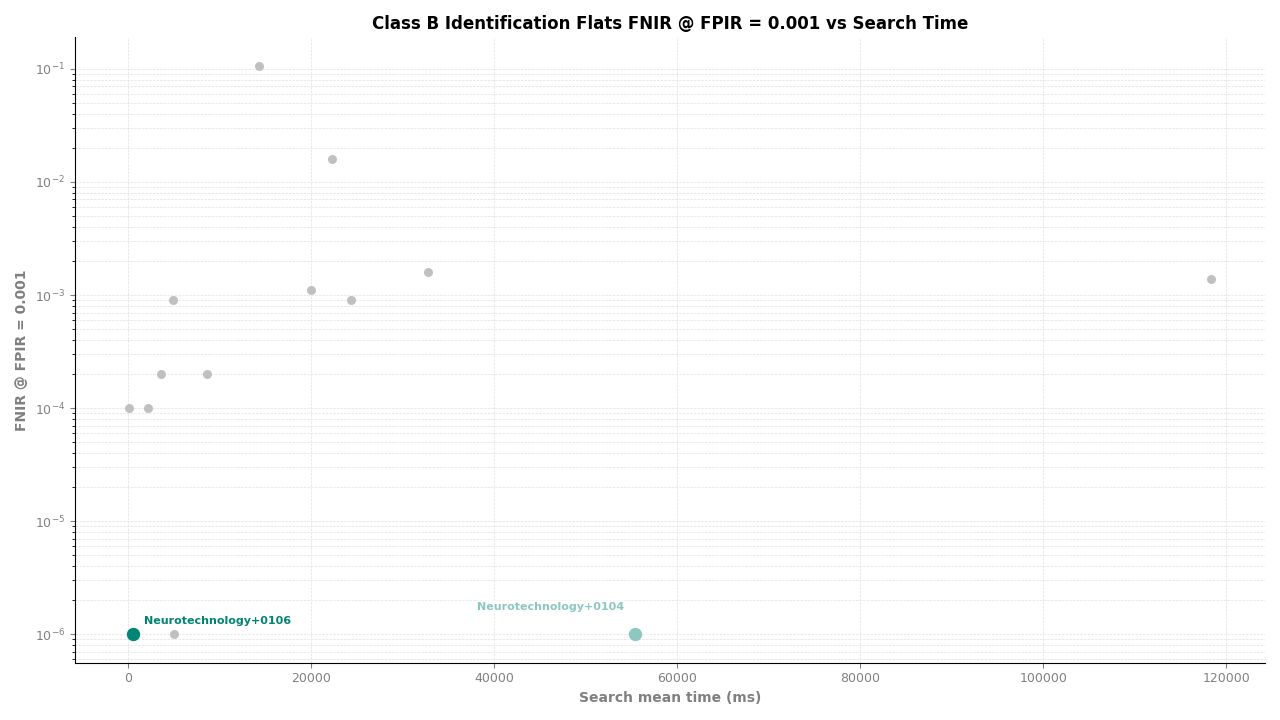
Identification Flats – FNIR at FPIR ≤ 0.001 vs. Search Time
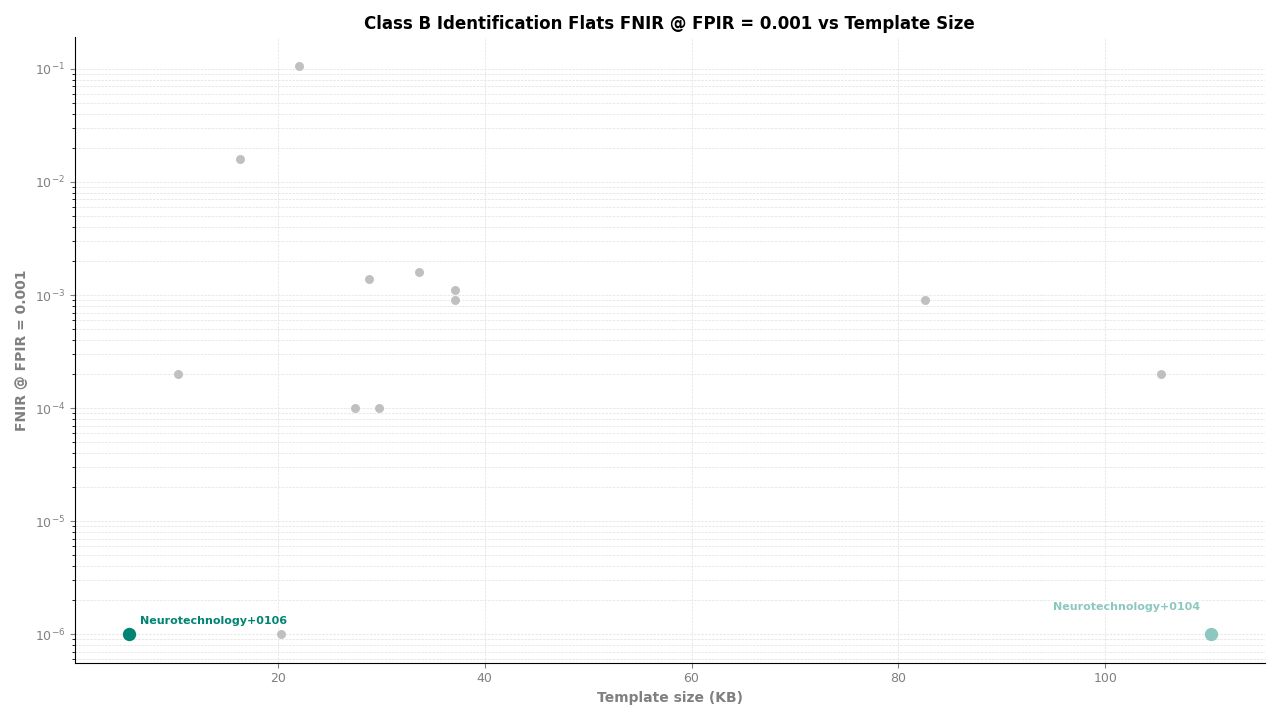
Identification Flats – FNIR at FPIR ≤ 0.001 vs. Template Size
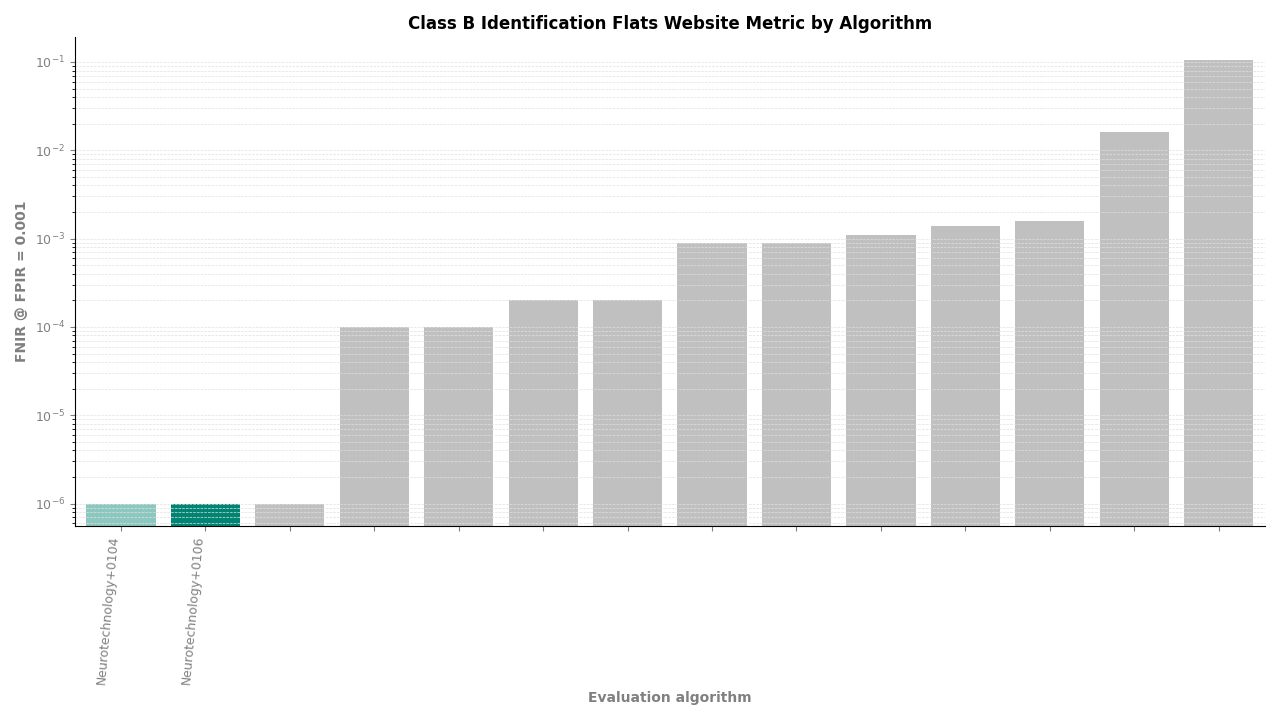
Identification Flats – FNIR at FPIR ≤ 0.001 by algorithm
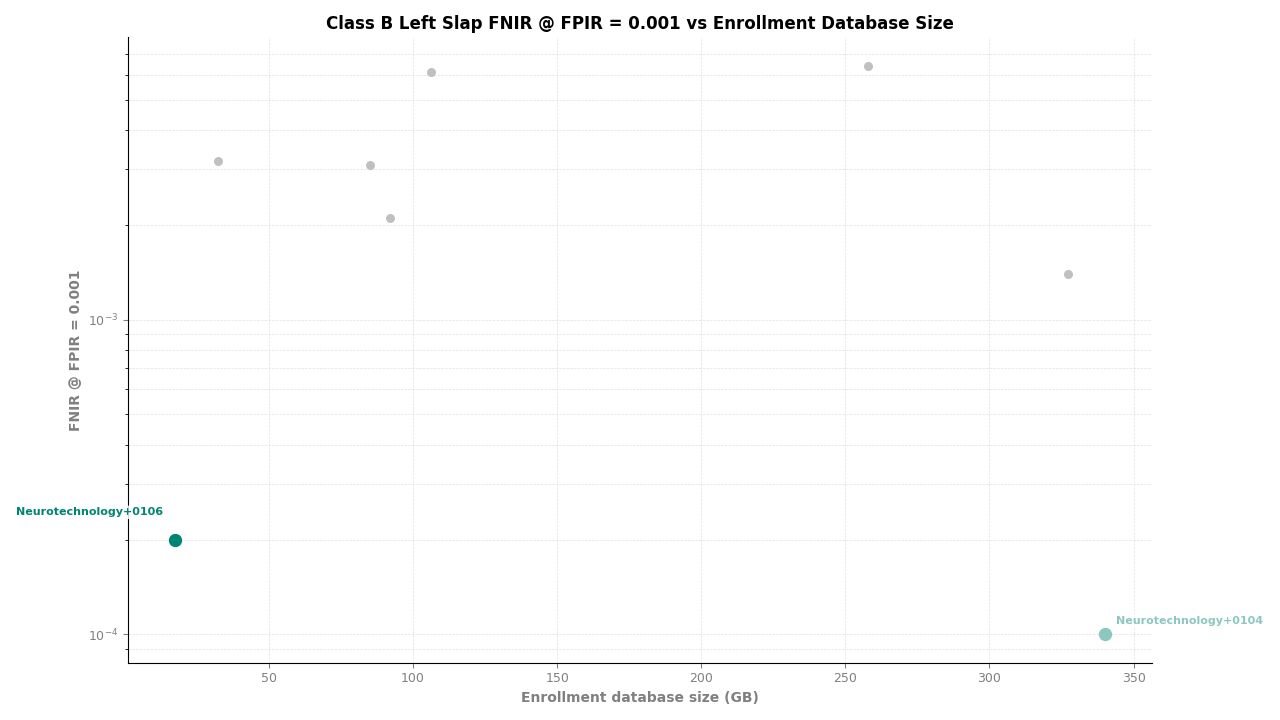
Left Slap – FNIR at FPIR ≤ 0.001 vs. Database Size
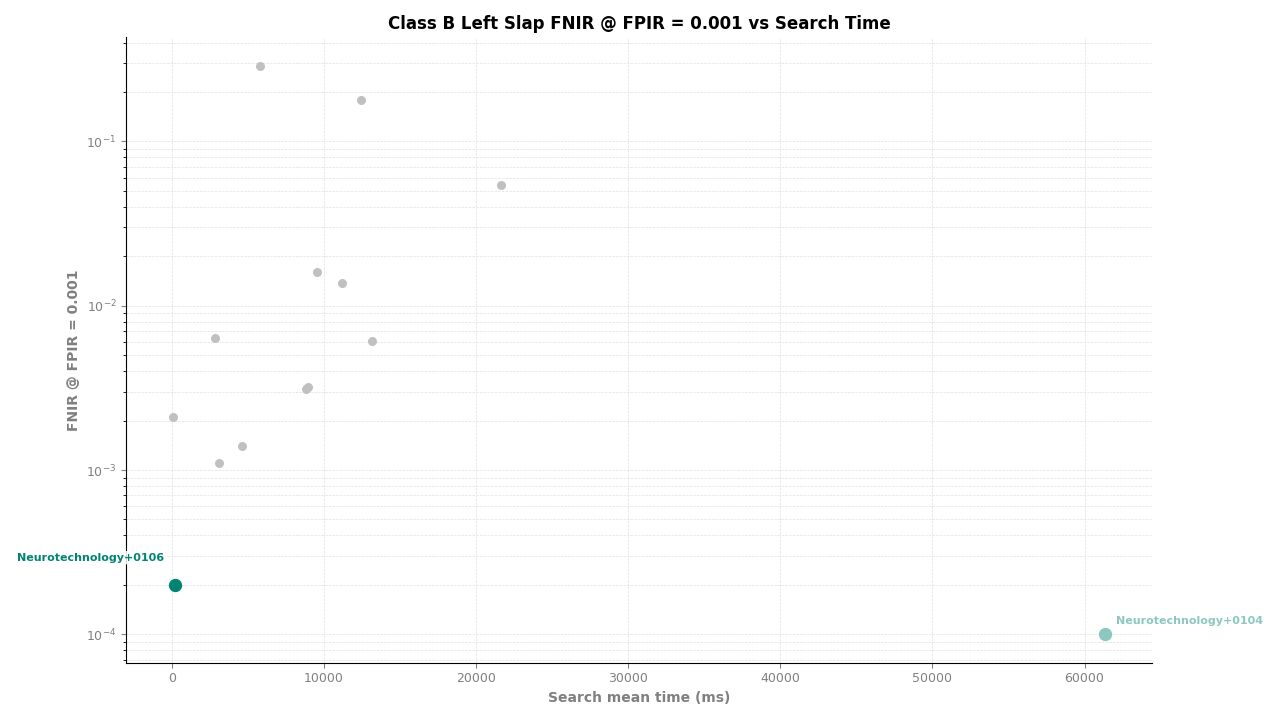
Left Slap – FNIR at FPIR ≤ 0.001 vs. Search Time
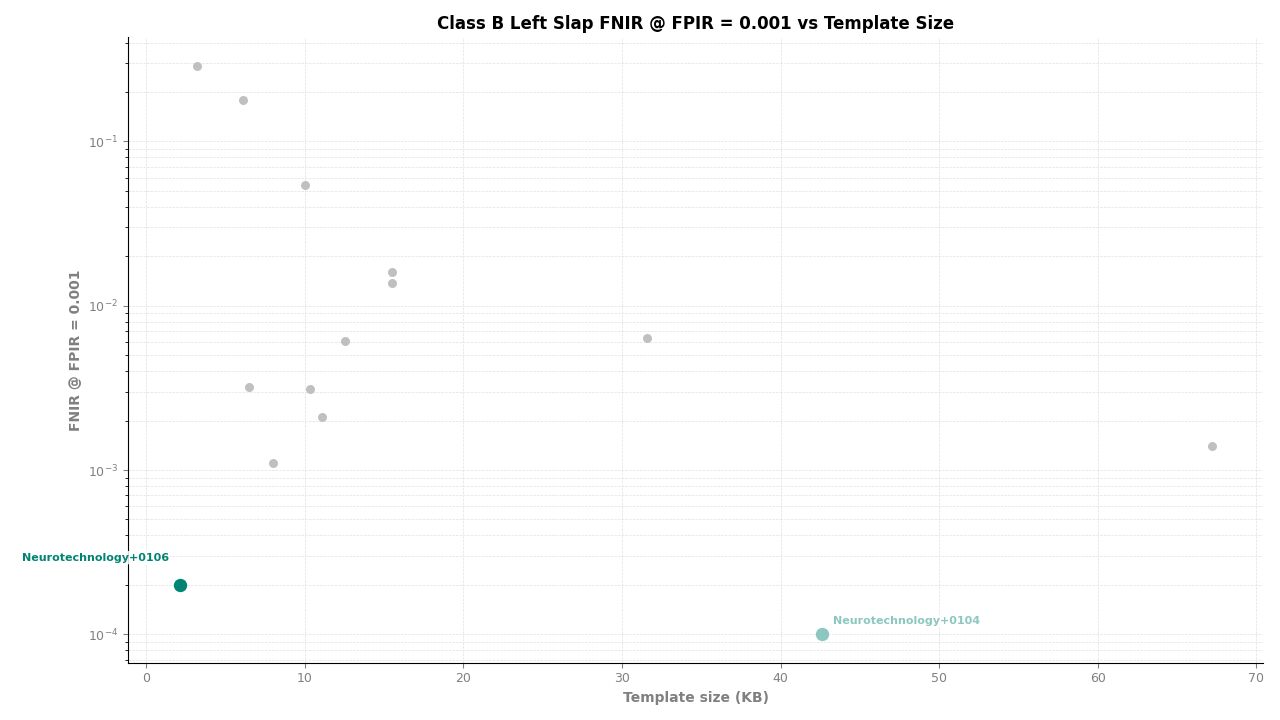
Left Slap – FNIR at FPIR ≤ 0.001 vs. Template Size
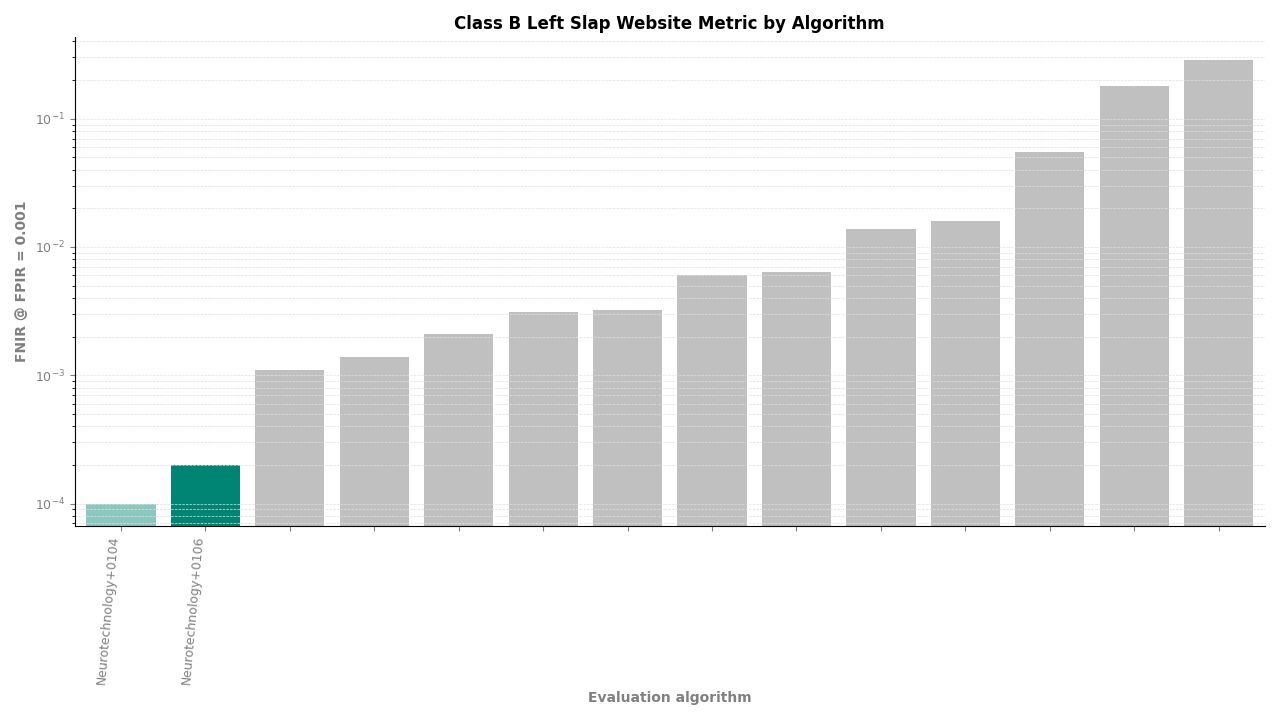
Left Slap – FNIR at FPIR ≤ 0.001 by algorithm
Right Slap – FNIR at FPIR ≤ 0.001 vs. Database Size
Right Slap – FNIR at FPIR ≤ 0.001 vs. Search Time
Right Slap – FNIR at FPIR ≤ 0.001 vs. Template Size
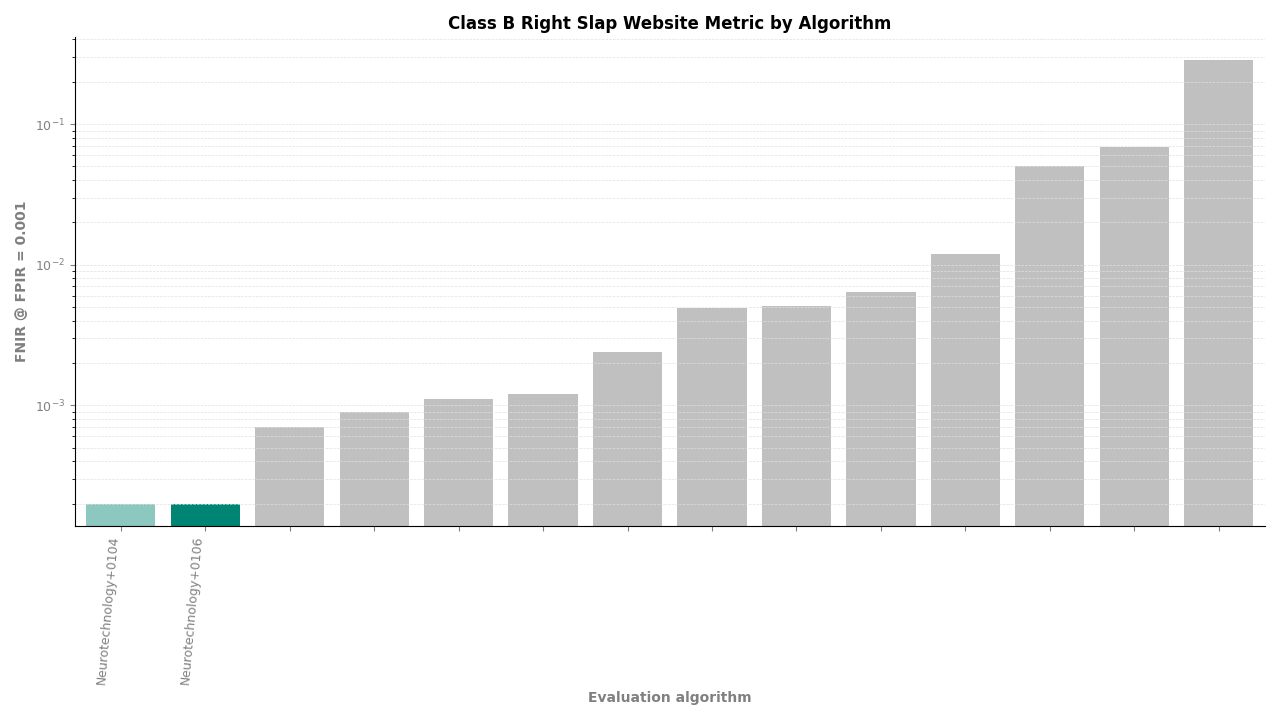
Right Slap – FNIR at FPIR ≤ 0.001 by algorithm
Class C – Ten-Finger Identification
Class C tests identification using plain impressions of all ten fingers in a 4-4-1-1 configuration, searched against a database of 5 million enrollment records – the largest database used in the evaluation.
Neurotechnology's algorithm ranked second of 11 in all Class C experiments. In the plain-finger-to-plain-reference experiment, the algorithm achieved an FNIR of 0.0004 at FPIR ≤ 0.001, placing it behind one participant while leading the remaining nine. In the plain-to-roll and roll-to-roll experiments, the algorithm achieved an FNIR of 0.0006 at FPIR ≤ 0.001, again ranking second.
Template creation produced zero failures across all probe types and across 5 million reference records.
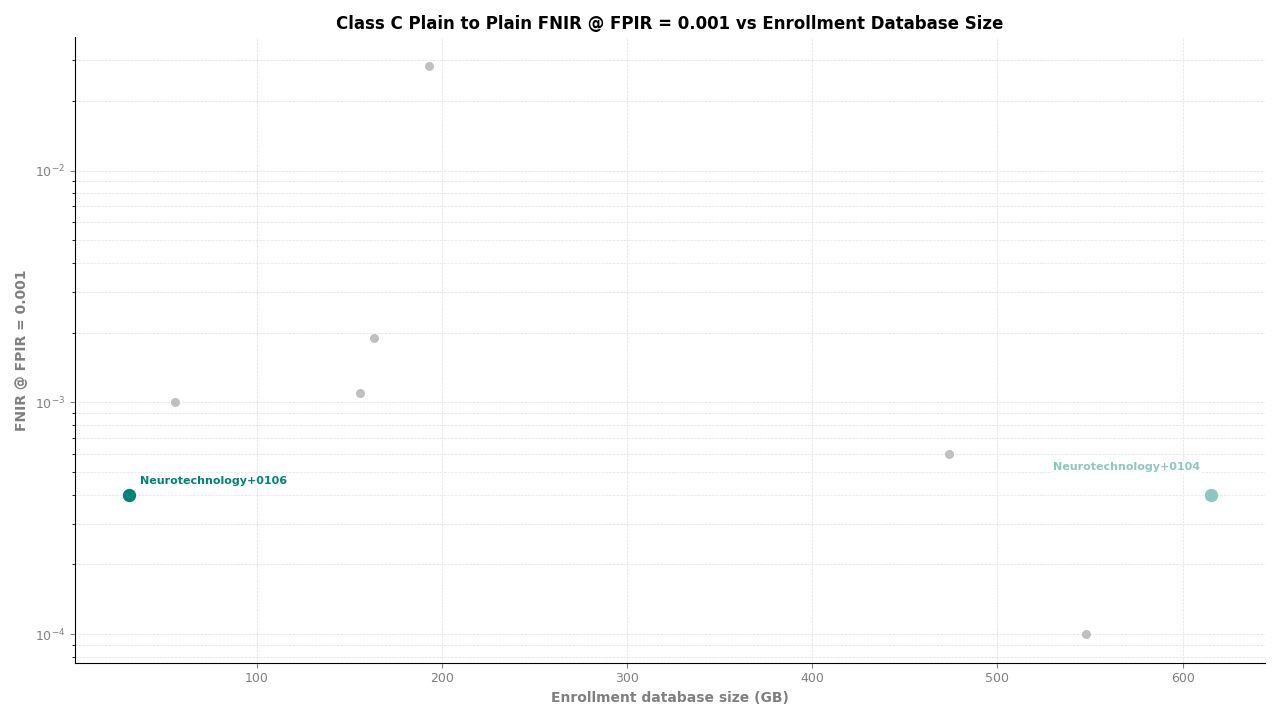
Plain to Plain – FNIR at FPIR ≤ 0.001 vs. Database Size
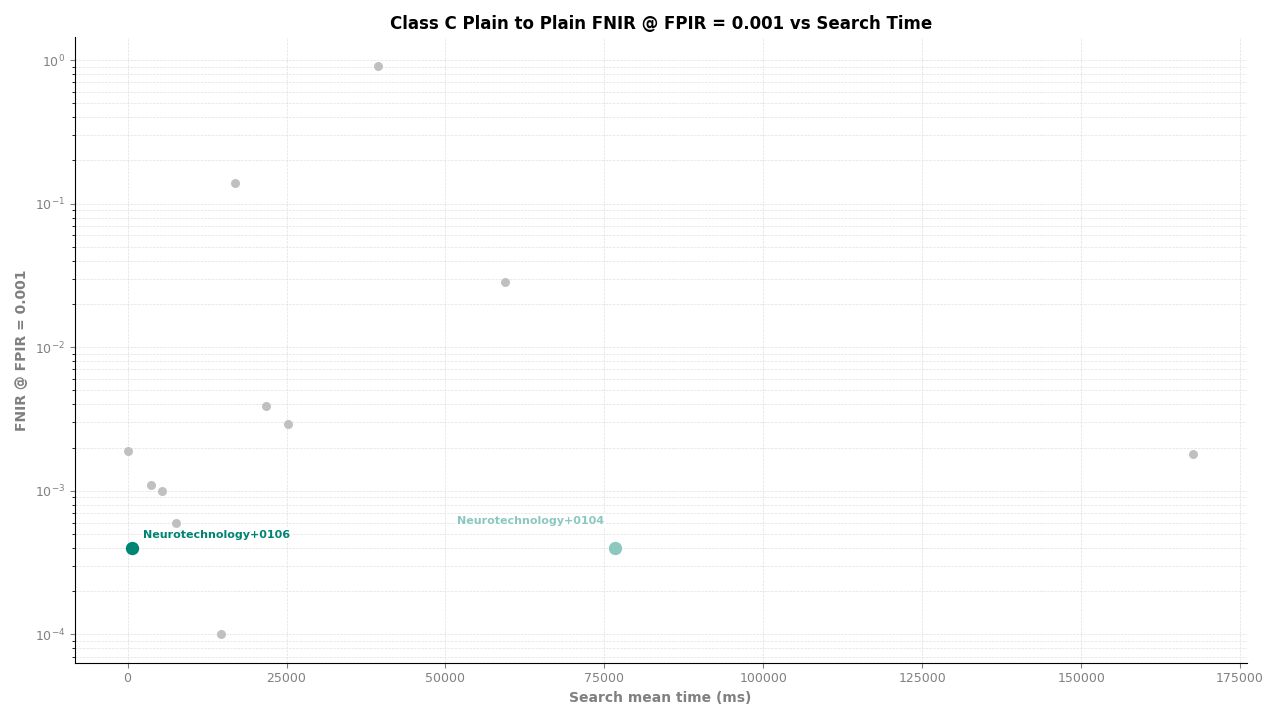
Plain to Plain – FNIR at FPIR ≤ 0.001 vs. Search Time
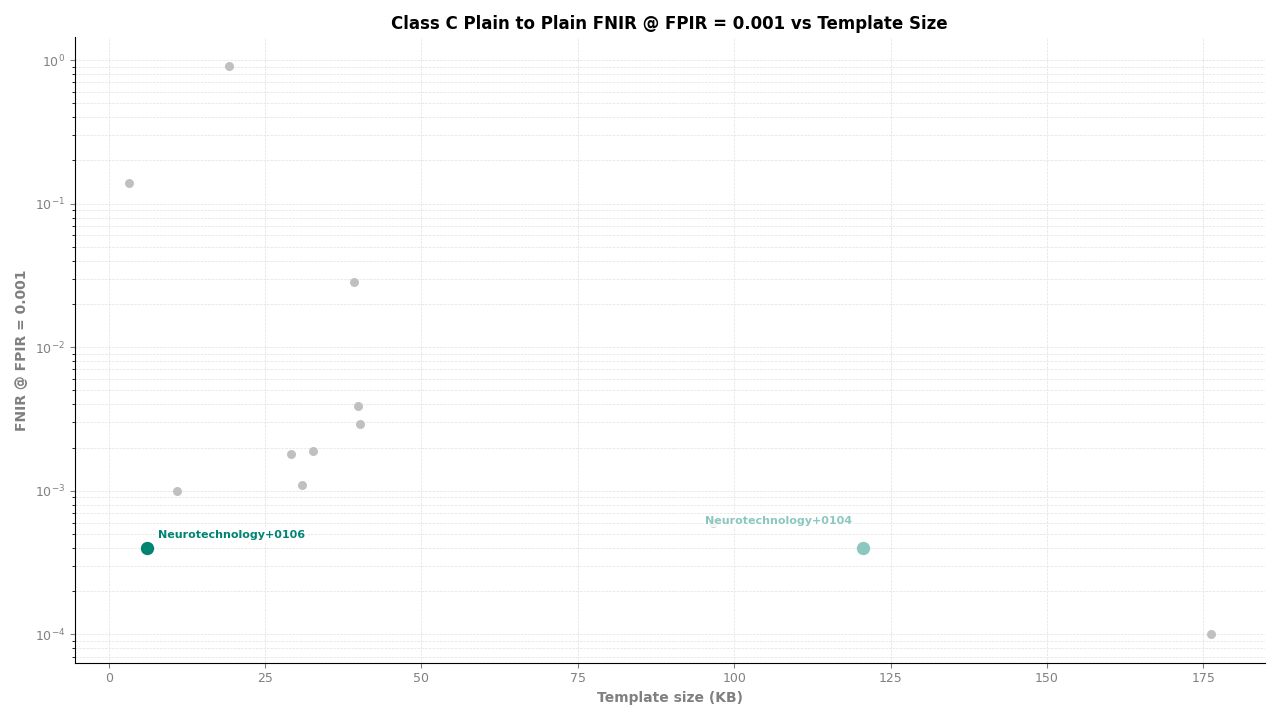
Plain to Plain – FNIR at FPIR ≤ 0.001 vs. Template Size
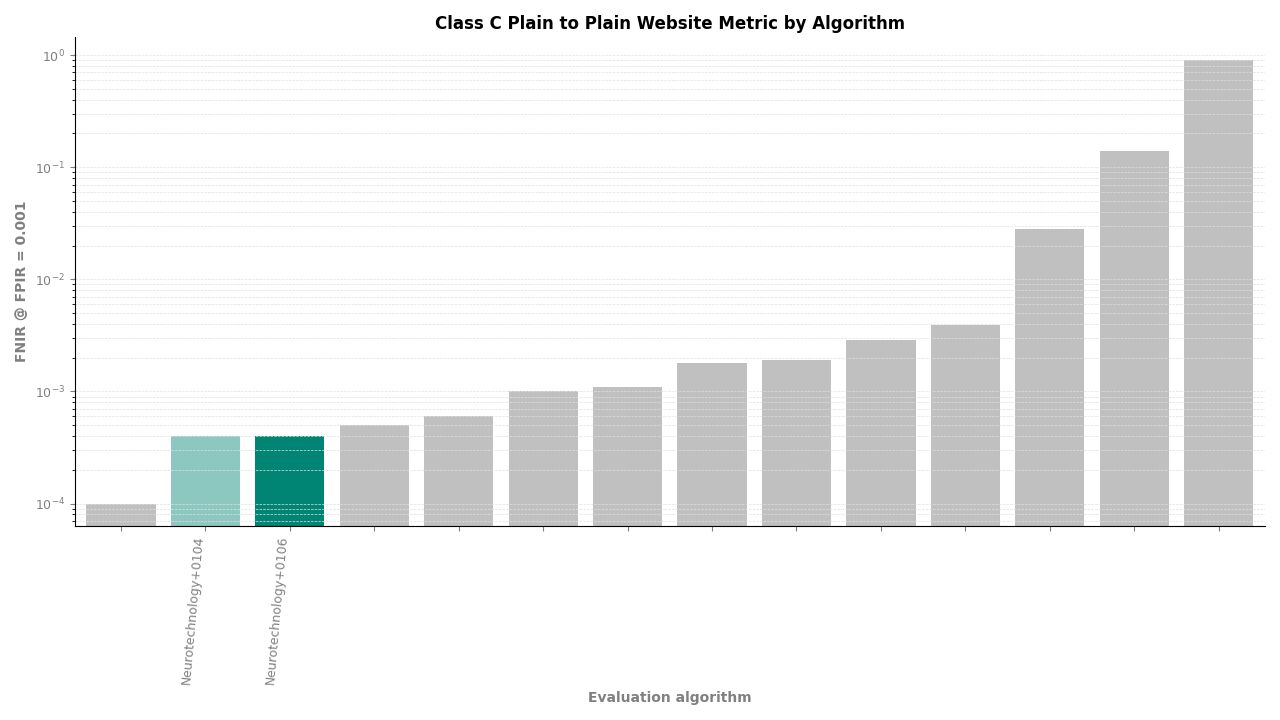
Plain to Plain – FNIR at FPIR ≤ 0.001 by algorithm
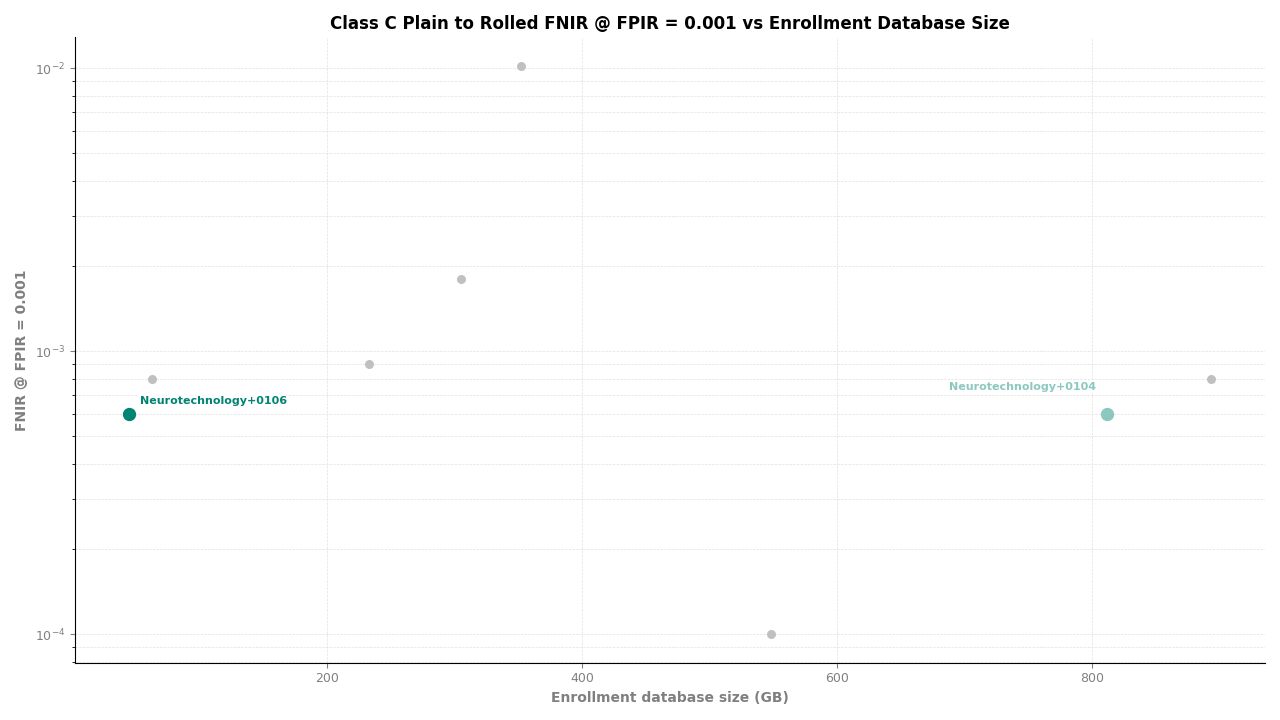
Plain to Rolled – FNIR at FPIR ≤ 0.001 vs. Database Size
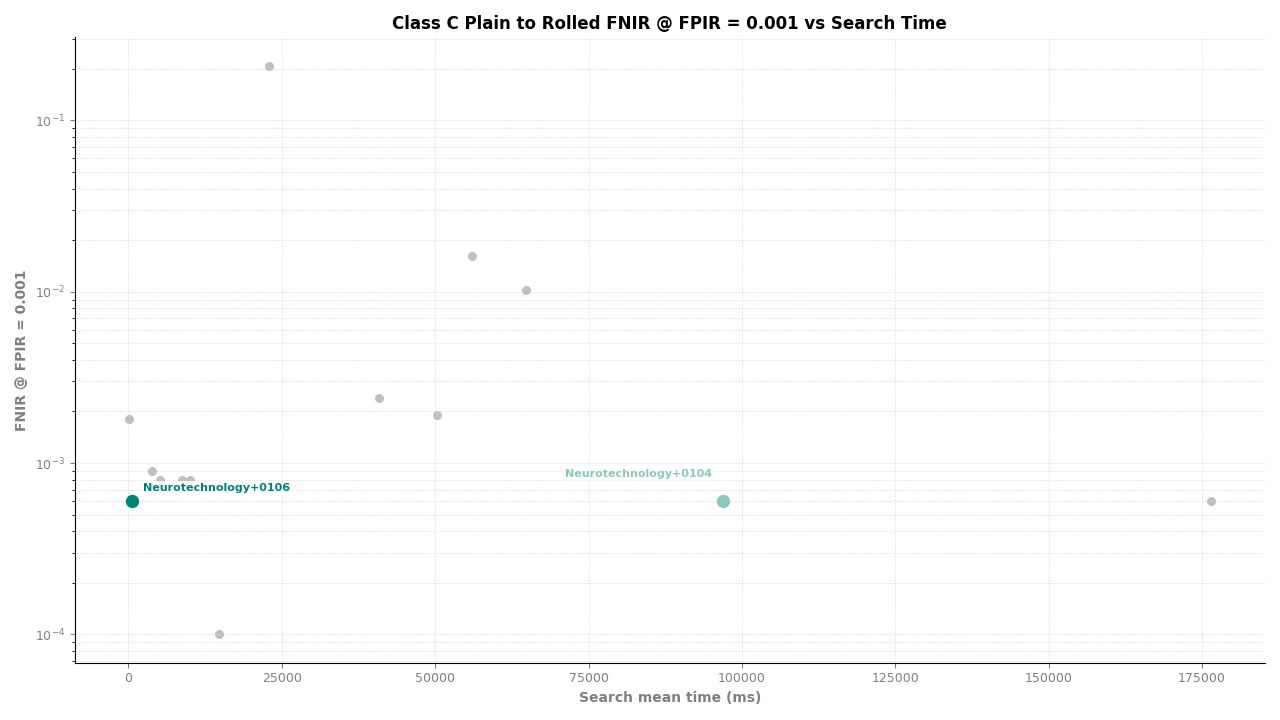
Plain to Rolled – FNIR at FPIR ≤ 0.001 vs. Search Time
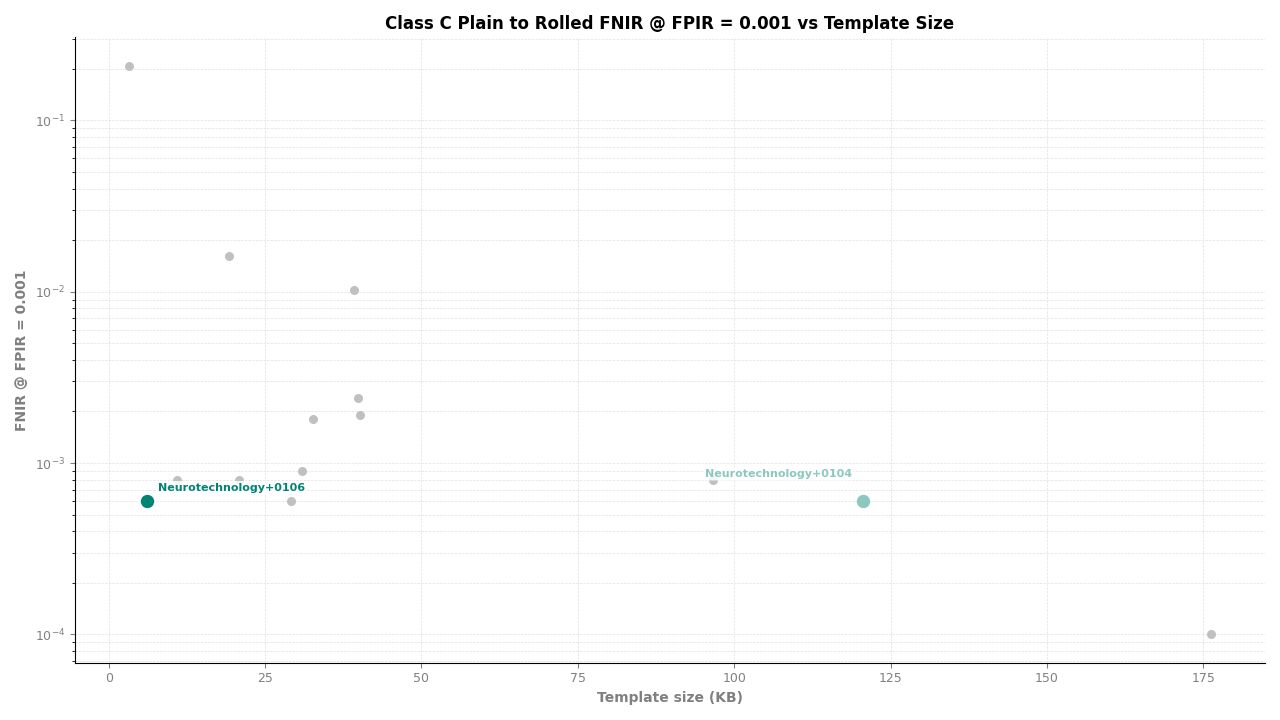
Plain to Rolled – FNIR at FPIR ≤ 0.001 vs. Template Size
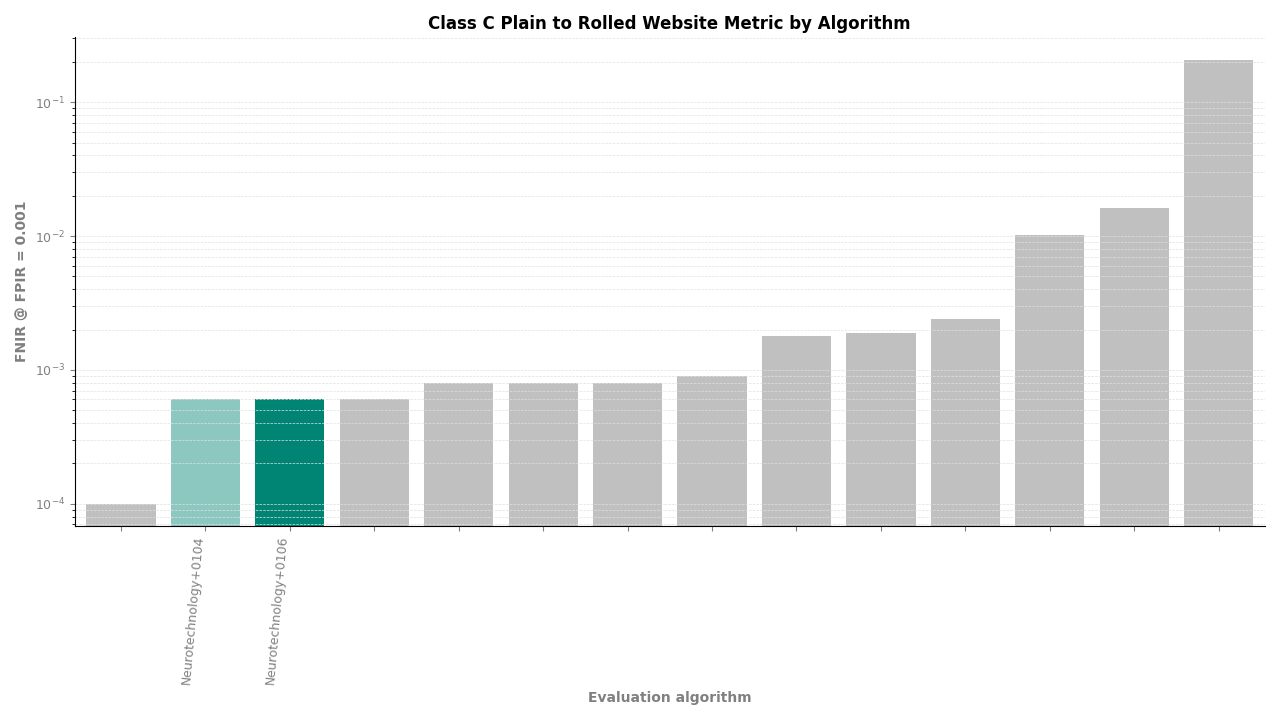
Plain to Rolled – FNIR at FPIR ≤ 0.001 by algorithm
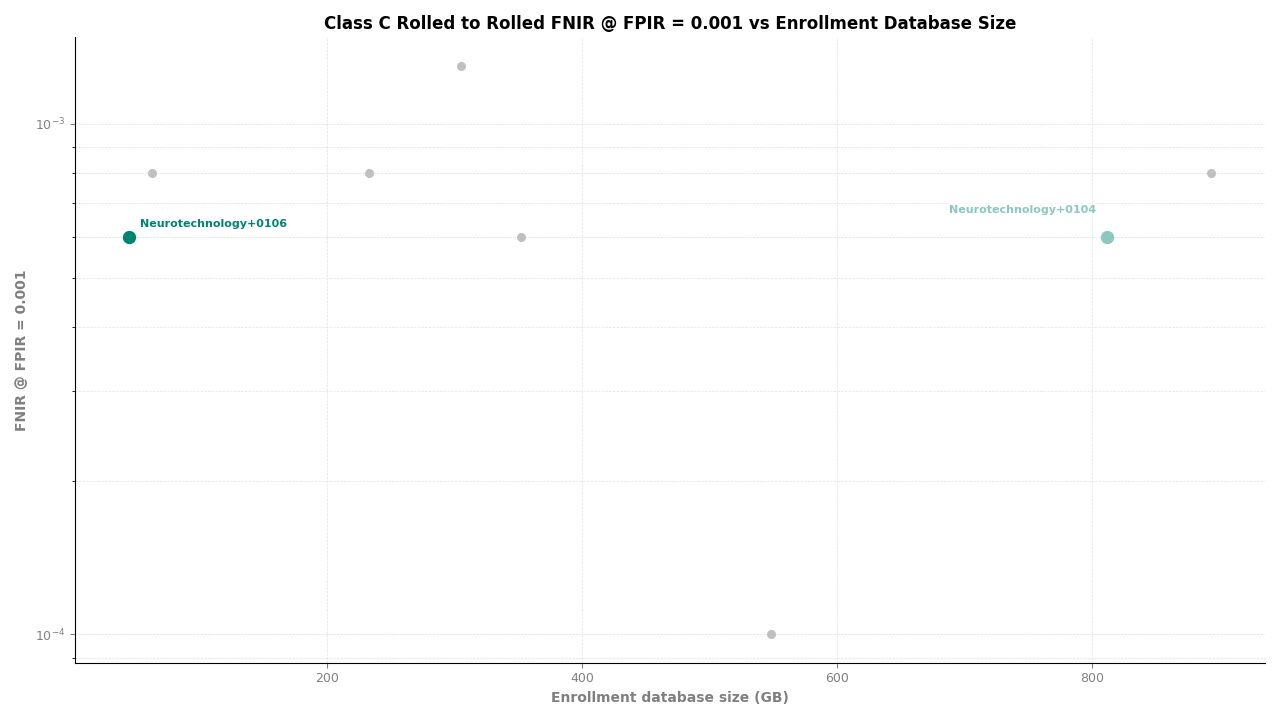
Rolled to Rolled – FNIR at FPIR ≤ 0.001 vs. Database Size
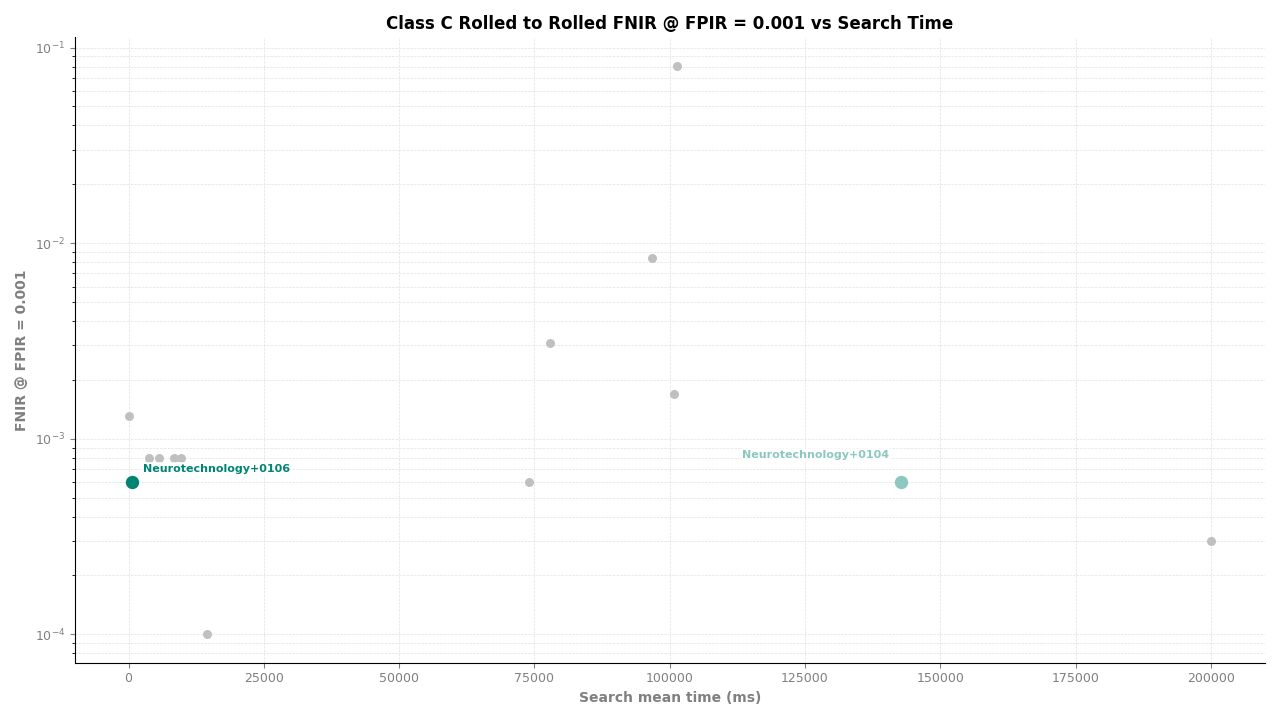
Rolled to Rolled – FNIR at FPIR ≤ 0.001 vs. Search Time
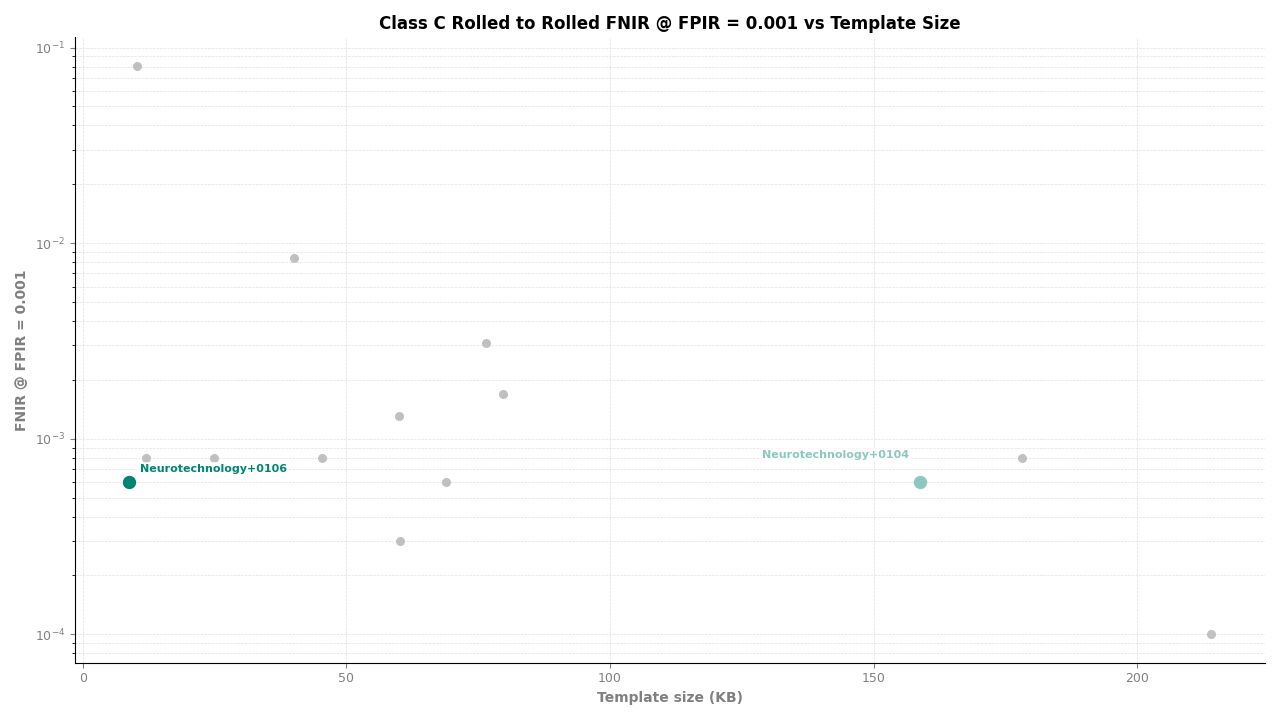
Rolled to Rolled – FNIR at FPIR ≤ 0.001 vs. Template Size
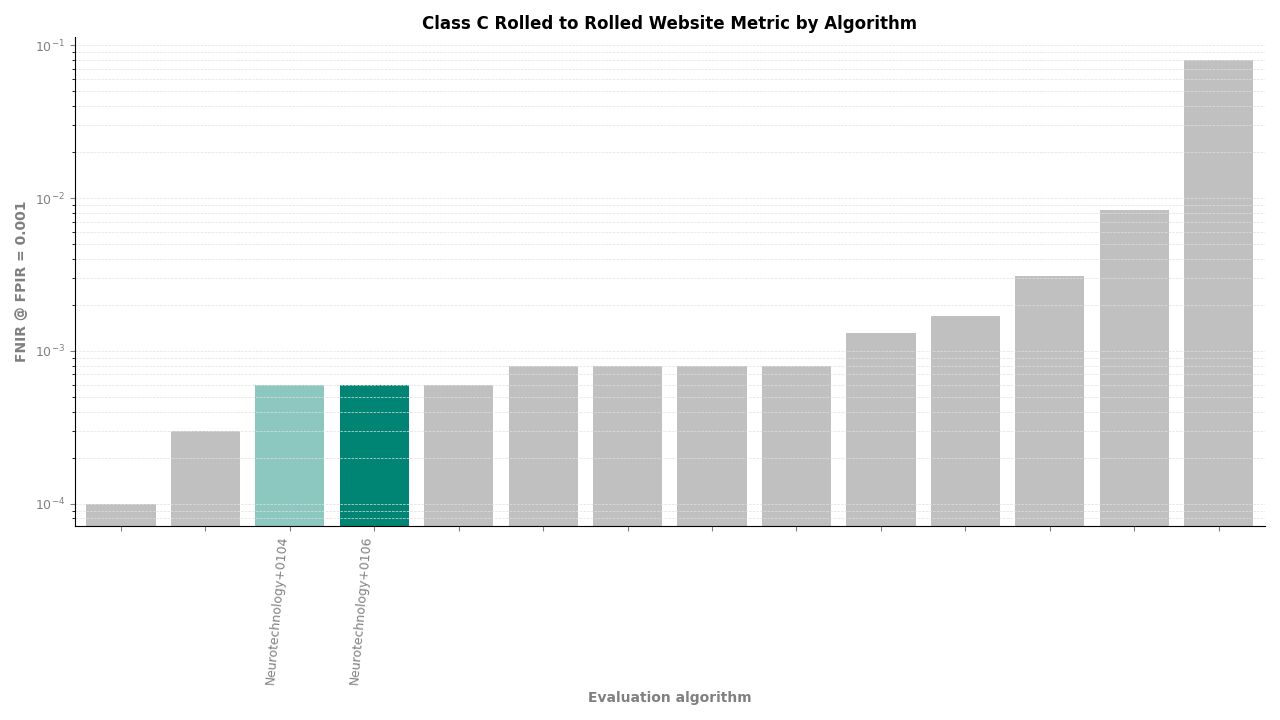
Rolled to Rolled – FNIR at FPIR ≤ 0.001 by algorithm
Processing speed and resource use
NIST measured template creation and search times for all submissions on identical hardware (Intel Xeon Gold 6254, single-threaded). For submission 0106, median search times against the largest database tested – 5 million ten-finger records – were 613 milliseconds for plain ten-finger probes and 560 milliseconds for rolled ten-finger probes. Median template creation times for ten-finger probes were approximately 7.6 seconds (plain) and 13.3 seconds (rolled).
The algorithm produced zero API timeout failures across all search experiments, including the 5 million record database.
Note: NIST results pages for this evaluation do not publish RAM consumption data for any participant. Per-submission comparisons of memory usage are not available from the published NIST data.
NIST also reports each submission's resource footprint. Templates are compact – a median of 0.6 kB for a single index finger, rising to 8.7 kB for a full set of ten rolled fingers. On the enrollment side, the finalized search databases occupied 1.8 GB for the 1.6 million index-finger records of Class A, 17.3 GB for the 3 million Identification Flat records of Class B, and from 31.0 GB (plain) to 44.1 GB (rolled) for the 5 million ten-finger records of Class C – the database that is loaded and searched at identification time.
Historical context
The FRIF TE E1N evaluation is the successor to FpVTE 2012, which was the last comparable evaluation of one-to-many fingerprint identification algorithms run by NIST before this series resumed – a gap of more than twelve years during which the technology landscape changed substantially.
See the NIST FRIF TE E1N official page for full evaluation methodology and all participant results.
Results shown from the FRIF TE E1N test do not constitute endorsement of any particular system by the U.S. Government.